

{kind=link}
As AI technology continues to evolve, running Large Language Models (LLMs) locally has become increasingly accessible. This guide explores the top 10 tools that enable developers and organizations to deploy and run LLMs on their own hardware in 2025.
Table of Contents
- 1. LM Studio
- 2. Ollama
- 3. LocalAI
- 4. Text Generation WebUI
- 5. GPT4All
- 6. llama.cpp
- 7. PrivateGPT
- 8. MLX
- 9. vLLM
- 10. ExLlama
1. LM Studio
LM Studio is a desktop application that lets you run AI language models directly on your computer. Through its interface, users find, download, and run models from Hugging Face while keeping all data and processing local.
The system acts as a complete AI workspace. Its built-in server mimics OpenAI's API, letting you plug local AI into any tool that works with OpenAI. The platform supports major model types like Llama 3.2, Mistral, Phi, Gemma, DeepSeek, and Qwen 2.5. Users drag and drop documents to chat with them through RAG (Retrieval Augmented Generation), with all document processing staying on their machine. The interface lets you fine-tune how models run, including GPU usage and system prompts.
Running AI locally does require solid hardware. Your computer needs enough CPU power, RAM, and storage to handle these models. Users report some performance slowdowns when running multiple models at once. But for teams prioritizing data privacy, LM Studio removes cloud dependencies entirely. The system collects no user data and keeps all interactions offline. While free for personal use, businesses need to contact LM Studio directly for commercial licensing.
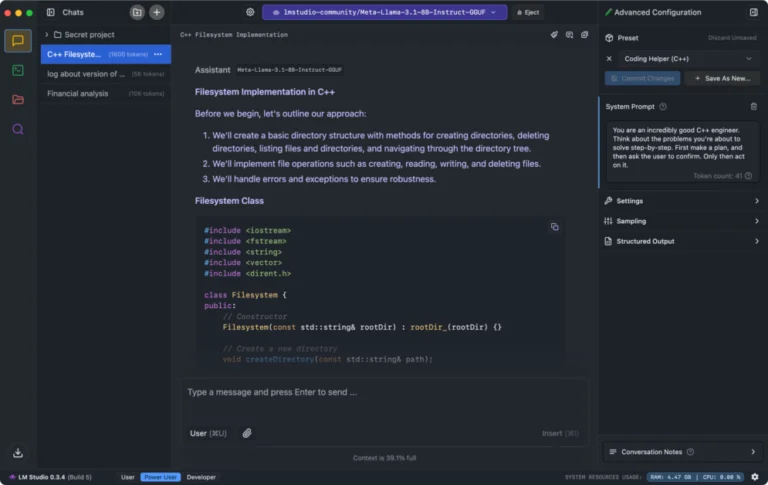
Website: https://lmstudio.ai
LM Studio has emerged as a leading solution for local LLM deployment, offering a user-friendly interface for managing and running various language models.
Key Features:
- Intuitive GUI for model management
- Support for multiple model formats
- Built-in model quantization
- Chat interface with conversation history
- API server functionality
- Cross-platform compatibility (Windows, macOS, Linux)
Benefits:
- Minimal technical expertise required
- Efficient resource utilization
- Real-time performance monitoring
- Easy model switching and comparison
- Integrated prompt engineering tools
2. Ollama
Ollama downloads, manages, and runs LLMs directly on your computer. This open-source tool creates an isolated environment containing all model components – weights, configurations, and dependencies – letting you run AI without cloud services.
The system works through both command line and graphical interfaces, supporting macOS, Linux, and Windows. Users pull models from Ollama's library, including Llama 3.2 for text tasks, Mistral for code generation, Code Llama for programming, LLaVA for image processing, and Phi-3 for scientific work. Each model runs in its own environment, making it easy to switch between different AI tools for specific tasks.
Organizations using Ollama have cut cloud costs while improving data control. The tool powers local chatbots, research projects, and AI applications that handle sensitive data. Developers integrate it with existing CMS and CRM systems, adding AI capabilities while keeping data on-site. By removing cloud dependencies, teams work offline and meet privacy requirements like GDPR without compromising AI functionality.
Website: https://ollama.ai
Ollama has gained popularity for its streamlined approach to running LLMs locally, particularly excelling in command-line operations.
Key Features:
- Command-line focused interface
- One-line model installation
- Custom model library
- GPU acceleration support
- REST API endpoints
- Container support
Benefits:
- Minimal resource overhead
- Fast model switching
- Easy integration with existing tools
- Active community support
- Regular performance updates
3. LocalAI
LocalAI is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that’s compatible with OpenAI API specifications for local inferencing. It allows you to run LLMs, generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families and architectures.
Website: https://localai.io
LocalAI provides a self-hosted alternative to cloud AI services, focusing on privacy and customization.
Key Features:
- OpenAI-compatible API
- Multi-model support
- Custom model training capabilities
- Embedded database integration
- Docker support
- Fine-tuning tools
Benefits:
- Complete data privacy
- Cost-effective scaling
- Customizable deployment options
- Enterprise-ready security
- Extensive documentation
4. Text Generation WebUI
Website: https://github.com/oobabooga/text-generation-webui
This open-source tool offers a comprehensive web interface for running and interacting with various language models.
Key Features:
- Rich web interface
- Multiple model format support
- Advanced parameter controls
- Training interface
- Extension system
- Multi-GPU support
Benefits:
- Highly customizable
- Active development community
- Extensive model compatibility
- Detailed performance metrics
- Regular feature updates
5. GPT4All
Website: https://gpt4all.io
GPT4All focuses on bringing powerful language models to consumer-grade hardware.
Key Features:
- Desktop application
- Cross-platform support
- Local model training
- Document analysis
- Chat interface
- API integration
Benefits:
- Low hardware requirements
- Privacy-focused design
- Regular model updates
- Community-driven development
- Extensive documentation
6. llama.cpp
Website: https://github.com/ggerganov/llama.cpp
A powerful C++ implementation for running LLM models efficiently on CPU hardware.
Key Features:
- CPU optimization
- 4-bit quantization
- Metal GPU acceleration
- CUDA support
- Cross-platform compatibility
- Low memory footprint
Benefits:
- Maximum performance
- Hardware flexibility
- Active development
- Strong community support
- Extensive model support
7. PrivateGPT
Website: https://github.com/imartinez/privategpt
PrivateGPT specializes in running LLMs for document analysis and question-answering tasks completely offline.
Key Features:
- Document processing
- Offline operation
- RAG support
- Multi-document analysis
- Custom knowledge base
- Privacy-focused design
Benefits:
- Complete data privacy
- Specialized for document analysis
- Efficient resource usage
- Enterprise-ready
- Regular security updates
8. MLX
Website: https://github.com/ml-explore/mlx
Apple's MLX framework optimizes LLM performance on Apple Silicon hardware.
Key Features:
- Apple Silicon optimization
- Array computation framework
- Automatic differentiation
- Python and C++ APIs
- Memory efficiency
- Metal performance shaders
Benefits:
- Maximum M1/M2 performance
- Efficient memory usage
- Native Apple integration
- Regular optimization updates
- Developer-friendly API
9. vLLM
Website: https://github.com/vllm-project/vllm
vLLM focuses on high-performance LLM inference with advanced optimization techniques.
Key Features:
- PagedAttention technology
- Continuous batching
- Multi-GPU support
- OpenAI-compatible API
- Docker integration
- Performance monitoring
Benefits:
- High throughput
- Low latency
- Efficient resource utilization
- Easy scaling
- Production-ready deployment
10. ExLlama
Website: https://github.com/turboderp/exllama
ExLlama specializes in optimized inference for Llama models on consumer hardware.
Key Features:
- GPU optimization
- Custom kernel implementation
- Memory efficiency
- 4-bit quantization
- Streaming generation
- Easy integration
Benefits:
- Maximum GPU performance
- Low memory requirements
- Fast inference speeds
- Regular optimization updates
- Active community support
Comparison Matrix
| Tool | GUI | API | GPU Support | Quantization | Multi-Model | Platform Support |
|---|---|---|---|---|---|---|
| LM Studio | ✅ | ✅ | ✅ | ✅ | ✅ | All |
| Ollama | ⌠| ✅ | ✅ | ✅ | ✅ | All |
| LocalAI | ✅ | ✅ | ✅ | ✅ | ✅ | All |
| Text Generation WebUI | ✅ | ✅ | ✅ | ✅ | ✅ | All |
| GPT4All | ✅ | ✅ | ✅ | ✅ | ✅ | All |
| llama.cpp | ⌠| ✅ | ✅ | ✅ | ✅ | All |
| PrivateGPT | ✅ | ✅ | ✅ | ✅ | ✅ | All |
| MLX | ⌠| ✅ | ✅* | ✅ | ✅ | macOS |
| vLLM | ⌠| ✅ | ✅ | ✅ | ✅ | All |
| ExLlama | ⌠| ✅ | ✅ | ✅ | ⌠| All |
*MLX GPU support is specific to Apple Silicon
Hardware Requirements
When choosing a tool for local LLM deployment, consider these general hardware recommendations:
Minimum Requirements:
- CPU: 4+ cores
- RAM: 16GB
- Storage: 50GB SSD
- GPU: 8GB VRAM (optional)
Recommended Requirements:
- CPU: 8+ cores
- RAM: 32GB
- Storage: 100GB+ NVMe SSD
- GPU: 16GB+ VRAM
Conclusion
The landscape of local LLM tools has evolved significantly in 2025, offering solutions for various use cases and technical requirements. Consider these factors when choosing a tool:
- Ease of Use: Tools like LM Studio and GPT4All offer user-friendly interfaces, while others prioritize performance and flexibility.
- Hardware Requirements: Consider your available computing resources and choose a tool that aligns with your hardware capabilities.
- Performance Needs: Tools like vLLM and ExLlama excel in performance optimization, while others focus on features and usability.
- Privacy Requirements: Solutions like PrivateGPT and LocalAI emphasize data privacy and security.
- Integration Needs: Consider API compatibility and integration capabilities with your existing infrastructure.
Regular updates and community support ensure these tools continue to evolve with the rapidly advancing field of AI technology.